















زمان تخمینی مطالعه: 18 دقیقه
شبکه عصبی کانولوشن (Convolutional Neural Network) یک نوع از شبکههای عصبی عمیق است که برای پردازش تصاویر و تشخیص الگوها در آنها طراحی شده است. این نوع از شبکههای عصبی به ویژه در حوزه بینایی ماشین و پردازش تصویر کاردبر گستردهای دارند. یک شبکه عصبی کانولوشن از لایههای مختلفی تشکیل شده است که از آن جمله باید به لایه پیچشی، لایه ادغام (Pooling) و لایه کاملا متصل (Fully Connected) اشاره کرد. این لایهها در تعامل با یکدیگر هستند که خروجی آنها باعث میشود به ویژگیها و اطلاعات مهمی دست پیدا کنیم.
لایه پیچشی ماهیت عملیاتی دارد و با استفاده از فیلترهای پیچشی، تصویر را اسکن میکند و ویژگیهای مختلف مانند لبهها، نقاط روشن و تاریک و الگوهای مشخص را استخراج میکند. این لایه در تعامل با تصویر ورودی است و خروجی نهایی را ارائه میکند. لایه ادغام (Pooling) برای کاهش ابعاد تصویر و کاهش تعداد پارامترها استفاده میشود. این لایه با خلاصهسازی و ادغام اطلاعات مهم، از جمله بزرگترین مقدارها یا میانگین مقادیر در هر ناحیه، تصویر را کوچکتر و سادهتر میکند. لایه کاملا متصل (Fully Connected) ویژگیهای استخراج شده را به عنوان ورودی دریافت میکند و آنها را به صورت غیرخطی ترکیب میکند تا به برچسب یا دستهبندی نهایی برسد. شبکههای عصبی کانولوشن به دلیل قابلیتشان در تشخیص الگوها و ویژگیهای تصویری، در بسیاری از برنامهها مثل تشخیص اشیا، تشخیص چهره، ترجمه ماشینی تصویری و خودران استفاده میشوند. آنها قدرتمندترین راهکارها برای پردازش تصویر را در اختیار متخصصان قرار میدهند.
شبکه عصبی پیچشی چیست؟
شبکه عصبی پیچشی (CNN) یک نوع شبکه عصبی مصنوعی است که برای پردازش دادههای تصویری طراحی شده است. CNNها از یک ساختار چند لایه استفاده میکنند که به آنها اجازه میدهد ویژگیهای مهم را از دادههای تصویری استخراج کنند. یک CNN از چند لایه زیر تشکیل شده است:
لایه ورودی: این لایه دادههای تصویری را دریافت میکند.
لایههای کانولوشن: این لایهها از فیلترهای پیچشی برای استخراج ویژگیهای مهم از دادههای تصویری استفاده میکنند.
لایههای کاملا متصل: این لایهها از یک شبکه عصبی پرسپترون چندلایه برای طبقهبندی یا پیشبینی دادههای تصویری استفاده میکنند.
لازم به توضیح است که فیلتر کانولوشن یک آرایه کوچک از اعداد است که به عنوان یک ماسک عمل میکند. فیلتر کانولوشن روی دادههای تصویری حرکت میکند و ویژگیهای مهم را استخراج میکند. در اینجا یک تابع ماکسیموم نیز وجود دارد که بزرگترین مقدار در یک آرایه را برمیگرداند و به منظور کاهش ابعاد دادههای تصویری مورد استفاده قرار میگیرد. در نهایت شبکه عصبی پرسپترون چندلایه یک نوع شبکه عصبی مصنوعی است که از یک سری گرههای پردازشی یا نورون تشکیل شده است. نورونها از طریق اتصالات وزندار به یکدیگر متصل هستند.
تاریخچه شبکه عصبی پیچشی
بدون اغراق باید بگوییم شبکه عصبی کانولوشن (CNN) یکی از مهمترین پیشرفتها در زمینه یادگیری عمیق و پردازش تصویر است. تاریخچه این شبکهها به دهه 60 میلادی بازمیگردد. به بیان دقیقتر، ایده اولیه شبکههای عصبی پیچشی به تحقیقات اولیه در زمینه پردازش تصویر توسط دو محقق به نامهای دیوید هابل و تریز هوف باز میگردد. آنها برای اولین بار نظریهای تحت عنوان (local receptive field) را مطرح کردند که ایده اصلی آن در نحوه عملکرد چشم انسان بود. این تئوری اساس اولیه شبکههای عصبی کانولوشن را شکل داد. در دهه 70 میلادی، تحقیقات بیشتری در زمینه شبکههای عصبی کانولوشن انجام شد. یکی از مدلهای مهم این دوره، مدل “Neocognitron” از یوکیهرو فوکوشیما بود که برای تشخیص الگوها در تصاویر طراحی شده بود. در دهه 80 و 90 میلادی تحقیقات بر روی CNN به دلیل محدودیت منابع محاسباتی و دادهها، کاهش یافت. اما در اواخر دهه 90 میلادی، مدل LeNet-5 توسط یان لوکان لیو و یان لوکان بوتویو در زمینه تشخیص ارقام در تصاویر متنی معرفی شد که مبنای شبکههای عصبی کانولوشن امروزی است.
در دهه 2000 میلادی با پیشرفت فناوریهای محاسباتی و توانایی انجام محاسبات پردازش تصویر با سرعت بالا، شبکههای عصبی کانولوشن دومرتبه مورد توجه قرار گرفتند. به طوری که در سال 2012 میلادی، مدل “AlexNet” توسط الکس کریژوسکی (AlexNet) و تیم تحت سرپرستی او معرفی شد که با استفاده از CNN، در مسابقه تشخیص تصاویر اینترنتی ImageNet با دقت بسیار بالا به پیروزی رسید و به این شکل اعتبار و شهرت شبکههای عصبی کانولوشن را بهبود بخشید. از آن زمان به بعد، شبکههای عصبی کانولوشن با تواناییهای برتر خود در تشخیص الگوها و تصاویر، در بسیاری از برنامهها و حوزهها مورد استفاده قرار گرفتهاند.
همچنین، در سالهای اخیر، شبکههای عصبی کانولوشن به صورت گسترده در بسیاری از برنامهها و حوزهها از جمله تشخیص اشیا، تشخیص چهره، خودروهای خودران، ترجمه ماشینی تصویری و بازیابی اطلاعات تصویری مورد استفاده قرار میگیرند. همچنین، با پیشرفتهای اخیر در زمینه یادگیری عمیق و شبکههای عصبی، مدلهایی با عمق و پیچیدگی بیشتری بر پایه شبکههای عصبی کانولوشن مانند VGG، ResNet، و Inception نیز توسعه یافتهاند.

معماری شبکه کانولوشن
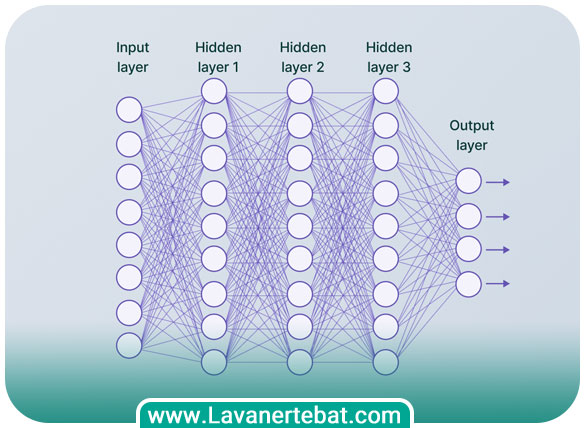
همانگونه که اشاره کردیم، معماری شبکه عصبی کانولوشن از چند لایه متوالی تشکیل شده است که هر لایه از واحدهای محاسباتی خاصی تشکیل شده است. این واحدها شامل لایههای کانولوشن، لایههای ادغام (Pooling) و لایههای کاملا متصل (Fully Connected) هستند. البته، معماری شبکه کانولوشن ممکن است با توجه به برنامه و وظیفهای که برای آن در نظر گرفته شده، متفاوت باشد اما معماری کلی این شبکهها به شرح زیر است:
لایه ورودی (Input Layer)
لایه ورودی (Input Layer)، اولین لایه در یک شبکه عصبی است و مسئولیت دریافت ورودیها است که آنها را به صورت مناسب برای شبکه عصبی آماده میکند. این لایه دارای یکسری ویژگیهای کلیدی است. اولین مورد ابعاد ورودی است. لایه ورودی باید بر مبنای اندازه ورودیهای مورد انتظار شبکه عصبی تعریف شود. بسته به نوع ورودی، میتواند ابعاد مختلفی داشته باشد. برای مثال، در شبکههای عصبی پیچشی (CNN) که تصاویر را پردازش میکنند، ابعاد لایه ورودی ممکن است عرض و ارتفاع تصویر و همچنین تعداد کانالهای رنگی را شامل شود. مورد بعد پیشپردازش دادهها است. لایه ورودی ممکن است مراحلی از پیشپردازش بر روی دادههای ورودی انجام دهد. این پیشپردازش میتواند شامل تبدیل دادهها به فرمت مناسب، مقیاسبندی، تغییر شکل یا هر پیشپردازش دیگری باشد که برای شبکه عصبی مورد نیاز است. لایه ورودی باید با نوع دادههای ورودی سازگاری داشته باشد. به طور مثال، اگر ورودیها بردارهای عددی هستند، لایه ورودی باید قادر به پذیرش ورودیهای عددی و بررسی ابعاد آنها باشد. در برخی موارد، لایه ورودی ممکن است وظیفه نرمالسازی دادههای ورودی را داشته باشد. این عملیات میتواند شامل تقسیم بر مقیاس، محو کردن تفاوتهای زمینهای و غیره باشد.
همچنین، لایه ورودی بررسی میکند که دادههای ورودی درست و کامل هستند و با قالب و نوع مورد انتظار سازگاری دارند. این بررسی میتواند شامل بررسی ابعاد و شکل دادهها، محدودیتهای مقادیر ورودی، بررسی نوع ورودی و غیره باشد. لایه ورودی در ارتباط با لایههای دیگر شبکه عصبی فقط باید به عنوان ورودی به لایههای بعدی ارسال شود. پس از انتقال دادهها از لایه ورودی، اطلاعات ویژگیها و الگوهای موجود در دادههای ورودی به صورت مشترک با سایر لایهها در شبکه عصبی به اشتراک گذاشته میشوند تا در نهایت خروجی مورد نظر را تولید کنند.
لایه کانولوشن (Convolutional Layer)
لایه کانولوشن یکی از مولفههای اصلی معماری شبکه عصبی کانولوشن است. این لایه برای استخراج ویژگیهای مهم از تصویر ورودی استفاده میشود. عملکرد لایه کانولوشن به این صورت است که با استفاده از هستههای کانولوشن بر روی تصویر ورودی عملیات پردازشی را انجام میدهد. هسته کانولوشن یک ماتریس از وزنها است که به صورت پنجرهای روی تصویر حرکت میکند و در هر مرحله یک عملیات ضرب نقطهای بین هسته و بخش متناظر تصویر را انجام میدهد. نتیجه این عملیات، یک نقشه ویژگی (feature map) است که ویژگیهای مهم تصویر را نشان میدهد. این لایه دارای یکسری ویژگیهای کلیدی است. اولین مورد استخراج ویژگی محلی است. لایه کانولوشن با استفاده از هستههای کانولوشن، ویژگیهای محلی را از تصویر استخراج میکند. به عنوان مثال، در تشخیص تصاویر چهره، هسته کانولوشن میتواند الگوهای سادهتری مانند لبخند، چشم و دستگاه بینایی را استخراج کند. مورد بعدی اشتراک وزنها است. یکی از ویژگیهای مهم لایه کانولوشن، اشتراک وزنها است. در هر مرحله از لایه کانولوشن، هسته کانولوشن به صورت یکسان بر روی تمام بخشهای تصویر اعمال میشود. این امر باعث کاهش تعداد پارامترها و حافظه مورد نیاز شبکه میشود و برای محاسبات سریعتر و کارآمدتر شبکه مفید است.
مورد بعدی انتقال ویژگیها است. لایه کانولوشن در لایههای متوالی، ویژگیهای پیچیدهتر را از ویژگیهای سادهتر استخراج میکند. به عبارت دیگر، این لایهها به تدریج ویژگیهای انتزاعی و سطح بالاتر را از تصویر استخراج میکنند. این انتقال ویژگیها به صورت سلسله مراتبی از اهمیت بالا برخوردار است. همچنین، لایه کانولوشن شامل پارامترهایی است که باید در طول فرآیند آموزش شبکه عصبی بهینهسازی شوند. این پارامترها شامل وزنهای هستههای کانولوشن و بایاس (bias) است. به طور کلی، وزنها برای تعیین اهمیت هر قسمت از تصویر ورودی در استخراج ویژگیها مورد استفاده قرار میگیرند، در حالی که بایاس میزان افزودن یا کاهش تاثیر نویز و عوامل تصادفی را کنترل میکند.
با توجه به توضیحاتی که ارائه کردیم باید بگوییم لایه کانولوشن در شبکه عصبی به صورت ترکیبی از چند هسته کانولوشن و لایههای دیگر مانند لایههای فعالسازی (activation) و لایههای تجمیع (pooling) به کار میرود تا ویژگیهای مهم و انتزاعی از تصاویر استخراج شوند و در نهایت در لایههای کاملا متصل (fully connected) برای دستهبندی استفاده شوند.
لایه ادغام (Pooling Layer)
لایه ادغام (Pooling Layer) یکی از لایههای شبکههای عصبی است که وظیفه خلاصهسازی دادهها را دارد. هدف اصلی لایه ادغام، کاهش تعداد پارامترها و ابعاد دادهها در جریان پردازش است، در حالی که اطلاعات مهم را حفظ میکند. این لایه دارای یکسری ویژگیها و نکات کلیدی است. اولین مورد ابعاد و نوع ادغام است. لایه ادغام میتواند بر روی ابعاد مختلف از دادهها عمل کند، مانند ابعاد فضایی تصاویر یا ابعاد زمانی دنبالهها. این لایه میتواند به صورت ماکسیمم (Max Pooling) عمل کند که مقدار بزرگترین عنصر در هر منطقه از ورودی را برای ادغام استفاده میکند، یا به صورت میانگین (Average Pooling) که میانگین مقادیر در هر منطقه را محاسبه و استفاده میکند.
لایه ادغام با استفاده از مفهومی که پنجره نام دارد به طول و عرض مشخص، منطقههایی را پویش میکند و عمل ادغام را بر روی آنها انجام میدهد. یکی از مزایای اصلی لایه ادغام، کاهش ابعاد دادهها است. این کاهش میتواند به تقلیل تعداد پارامترها و محاسبات مورد نیاز برای شبکه عصبی کمک کند و همچنین مانع بروز مشکلاتی مثل بیشبرازش (overfitting) و کاهش پیچیدگی مدل شود. در حالی که لایه ادغام ابعاد را کاهش میدهد، سعی میکند اطلاعات مهم و ویژگیهای قابل توجه را در دادهها حفظ کند. برای مثال، در لایه ادغام با عمل بیشینه کردن، مقدار بزرگترین عنصر در هر منطقه انتخاب شده و در خروجی نگه داشته میشود که نشاندهنده ویژگیهای مهم در هر ناحیه است.
لایه ادغام معمولا بین لایههای پیچشی (Convolutional Layers) در شبکههای عصبی پیچشی استفاده میشود. با اعمال لایه ادغام به ترتیب بر روی ورودیهای پیچشی، اطلاعات محلی و ویژگیهای مهم در دادهها استخراج میشوند و ابعاد دادهها کاهش مییابد. این کاهش ابعاد و استخراج ویژگیها باعث میشود که شبکه عصبی قادر به تشخیص الگوها و ویژگیهای مهم در دادهها شود.
لایه کاملا متصل (Fully Connected Layer)
لایه کاملا متصل (Fully Connected Layer) یکی از انواع لایههای شبکههای عصبی است که تمام ورودیها را به یکدیگر مرتبط میکند. در این لایه، هر نورون (یا واحد) از لایه قبلی با همه نورونها (یا واحدها) در لایه فعلی متصل است. به عبارت دیگر، هر واحد در لایه کاملا متصل با تمام ورودیهای قبلی در ارتباط است و محاسبات خطی و غیرخطی روی این ورودیها انجام میشود. این لایه دارای یکسری ویژگیهای کلیدی است. اولین مورد اتصال کامل است. در لایه کاملا متصل، هر واحد با تمام ورودیهای قبلی ارتباط دارد. بنابراین، تعداد پارامترهایی که باید در این لایه آموزش داده شود، بیشترین تعداد پارامترها در شبکه عصبی است و به طور کلی برابر با ضرب تعداد ورودیها و تعداد واحدها است. هر واحد در لایه کاملا متصل میتواند دارای یک تابع فعالسازی غیرخطی باشد. این تابع فعالسازی به منظور افزایش قدرت شبکه در پردازش تصاوی پیچیده مورد استفاده قرار میگیرد تا بتواند فرآیند تشخیص الگوهای غیرخطی را در دادهها تسهیل میکند.
هر واحد در لایه کاملا متصل یک تبدیل خطی بر روی مجموعه ورودیها انجام میدهد. این تبدیل شامل ضرب داخلی وزنها (weights) با ورودیها و اضافه کردن یک عدد بایاس (bias) است. وزنها و بایاسها به عنوان پارامترهای قابل آموزش در این لایه محسوب میشوند و هدف آموزش، به دست آوردن مقادیر بهینه برای آنها است. لایه کاملا متصل به عنوان یک لایه پردازشی، اطلاعات را از لایه قبلی دریافت کرده و آنها را به لایه بعدی انتقال میدهد. این لایه معمولا برای استخراج ویژگیهای پیچیده و ترکیبی از ورودیها استفاده میشود و در تصمیمگیری نهایی و دستهبندی استفاده شود. به طور کلی، استفاده از لایه کاملا متصل در شبکههای عصبی به ویژه در شبکههای عصبی پیچشی (CNN) رایج است. به عنوان مثال، بعد از چند لایه پیچشی که ویژگیها را استخراج میکنند، ورودیها به یک یا چند لایه کاملا متصل میرسند تا ویژگیها را ترکیب کنند و نهایتا خروجی را تولید کنند. این لایههای کاملا متصل معمولا قبل از لایههای خروجی در شبکه قرار میگیرند. به کارگیری لایه کاملا متصل در شبکه عصبی به دلیل قدرت بالا و قابلیت ترکیب ویژگیها، میتواند در تشخیص الگوها و دستهبندی دادهها موثر باشد. با این حال، به دلیل تعداد بالای پارامترها، این لایه ممکن است منجر به افزایش میزان پیچیدگی و ریسک بیشبرازش شود. بنابراین، معمولا با استفاده از تکنیکهایی مانند Dropout این مشکلات کنترل میشوند.
لایه خروجی (Output Layer)
لایه خروجی (Output Layer)، لایهای در شبکههای عصبی است که نتیجه نهایی را تولید میکند. این لایه معمولا در انتهای شبکه قرار میگیرد و بسته به نوع مسئله، وظایف مختلفی از جمله دستهبندی، رگرسیون، تشخیص الگو و ترجمه متن را انجام میدهد. این لایه نیز دارای یکسری ویژگیهای کلیدی است. لایه خروجی معمولا دارای یک تابع فعالساز خاص است که وابسته به نوع مسئله و نوع خروجی استفاده میشود. برای مسایل دستهبندی دو کلاسه، معمولا از تابع سیگموید (sigmoid) استفاده میشود، در حالی که برای مسایل دستهبندی چند کلاسه، تابع softmax استفاده میشود. برای مسائل رگرسیون، معمولا تابع (identity) بدون تغییر استفاده میشود.
تعداد واحدهای لایه خروجی متناسب با تعداد کلاسها یا بعد خروجی است. به عنوان مثال، در مساله دستهبندی دو کلاسه، معمولا از یک واحد استفاده میشود که مقدار خروجی آن نشاندهنده احتمال تعلق به کلاس مثبت است. در مسایل دستهبندی چند کلاسه، تعداد واحدها برابر با تعداد کلاسها است و هر واحد نشاندهنده احتمال تعلق به یک کلاس مشخص است. خروجی لایه فوق معمولا تفسیری دارد که بسته به نوع مسئله متفاوت است. برای مسائل دستهبندی، احتمالات تعلق به هر کلاس قابل تفسیر هستند و کلاس با بیشترین احتمال به عنوان پاسخ انتخاب میشود. برای مسایل رگرسیون، مقدار خروجی مستقیما به عنوان پیشبینی نهایی استفاده میشود.
لایه خروجی معمولا با یک تابع هزینه (loss function) مرتبط است که میزان تفاوت بین خروجی مدل و خروجی مورد انتظار را اندازهگیری میکند. هدف مدل عصبی استفاده شده در آموزش، کمینه کردن تابع هزینه است. در بعضی از مسائل، لایه خروجی میتواند برای نمونهبرداری مورد استفاده قرار بگیرد. به عنوان مثال، در مسائل ترجمه متن، لایه خروجی میتواند به منظور توزیع احتمال کلمات به عنوان خروجی مورد استفاده قرار گیرد یا با استفاده از روشهای نمونهبرداری، فرآیند ترجمه کلمات را انجام دهد.
مزایای شبکه عصبی CNN
شبکههای عصبی پیچشی یکسری ویژگیهای کلیدی دارند که باعث شده در زمینههای مختلفی مورد استفاده قرار گیرند. برخی از این ویژگیها به شرح زیر هستند:
استخراج ویژگی خودکار: یکی از مزایای اصلی شبکههای عصبی CNN قابلیت استخراج خودکار ویژگیهای مهم از تصاویر است. با استفاده از لایههای پیچشی و pooling، این شبکهها قادر به شناسایی الگوها و ویژگیهای هرچه بیشتر در تصاویر هستند. این ویژگیها به صورت خودکار و بدون نیاز به تعیین دستی ویژگیها توسط انسان استخراج میشوند.
پارامترهای قابل یادگیری: شبکههای عصبی CNN قادر به یادگیری از دادهها هستند. این به معنای آن است که با آموزش شبکه بر روی دادههای ورودی و تنظیم وزنها و بایاسها، شبکه عصبی قادر خواهد بود الگوهای موجود در دادهها را یاد بگیرد و بتواند بهترین تصمیمگیری را برای ورودیهای جدید انجام دهد.
تقسیم مکانی: شبکههای عصبی CNN توانایی تقسیم مکانی را دارند. به این معنا که این شبکهها میتوانند الگوها و ویژگیها را در مکانهای مختلف تصویر تشخیص دهند. به عبارت دیگر، شبکه عصبی CNN قادر است به صورت موازی و در بخشهای مختلف تصویر، اطلاعات را پردازش کند و ارتباطات مکانی مهمی را در تصویر تشخیص دهد.
کاهش تعداد پارامترها: با استفاده از لایههای پیچشی و لایههای pooling layers، شبکههای عصبی CNN قادر به کاهش تعداد پارامترهای قابل یادگیری هستند. این ویژگی باعث میشود که آموزش و استفاده از این شبکهها سریعتر و کارآمدتر باشد، به خصوص در مسایلی که دادهها حجم بالا یا ابعاد بزرگی دارند مانند تصاویر با ابعاد بالا.
مقاومت در برابر تغییرات مکانی: شبکههای عصبی CNN مقاومت بالایی در برابر تغییرات مکانی در تصاویر دارند. به عبارت دیگر، اگر الگوها یا ویژگیها در تصویر منتقل شوند یا موقعیتشان تغییر کند، شبکه عصبی CNN همچنان قادر است آنها را تشخیص دهد.
قابلیت استفاده مجدد از وزنها: در شبکههای عصبی CNN، لایههای پیچشی محاسباتی وجود دارند که از فیلترهای قابل یادگیری تشکیل شدهاند. این فیلترها قابل استفاده مجدد هستند و میتوانند در تشخیص الگوها و ویژگیها در تصاویر مختلف مورد استفاده قرار گیرند. این ویژگی باعث کاهش تعداد پارامترهای قابل یادگیری و افزایش کارایی شبکه میشود.
معایب شبکه عصبی CNN
در شرایطی که شبکههای فوق مزایای درخشانی در اختیار ما قرار میدهند، اما معایبی نیز دارند. برخی از این معایب به شرح زیر هستند:
پیچیدگی محاسباتی: شبکههای عصبی CNN به دلیل ساختار پیچیده و تعداد زیاد لایهها و پارامترها، نیاز به قدرت محاسباتی بالا و منابع سختافزاری قدرتمند دارند. آموزش و استفاده از این شبکهها نیازمند زمان زیادی است، به طوری که باید از هستههای پردازشی موازی گرافیکی زیادی استفاده شود.
نیاز به حجم زیادی از دادهها: شبکههای عصبی CNN برای دستیابی به دقت و عملکرد بالا، نیاز به حجم زیادی از دادهها دارند که جمعآوری و پالایش این دادهها به زمان و هزینه زیادی نیاز دارد.
حساسیت به پارامترهای آموزشی: شبکههای عصبی CNN حساسیت زیادی به پارامترهای آموزشی مانند نرخ یادگیری (learning rate) و تعداد دورههای آموزش (epochs) دارند. انتخاب نادرست این پارامترها میتواند به نتایج ضعیف یا عملکرد نامناسب شبکه منجر شود. تنظیم بهینه پارامترهای آموزشی نیاز به تجربه و آزمون و خطا دارد.
نیاز به دادههای متوازن: شبکههای عصبی CNN برای دستیابی به عملکرد بهتر و دقت بالا، نیاز به دادههای متوازن دارند. به این معنا که تعداد نمونههای هر دسته در مجموعه داده باید تقریبا یکسان باشد. در غیر این صورت، شبکه ممکن است به سمت دستههایی با تعداد نمونه بیشتر جهت تصمیمگیری متمایل شود و نتایج نادرستی تولید کند.
قابلیت تفسیر: شبکههای عصبی CNN معمولا به عنوان مدلهای جعبه سیاه شناخته میشوند، به این معنی که فرآیند تصمیمگیری آنها برای انسانها قابل فهم وقابل تفسیر نیست. شبکههای عصبی CNN برای استخراج ویژگیها و انجام پردازشهای پیچیده طراحی شدهاند، اما تحلیل دقیق و تفسیر نحوه کارکرد آنها ممکن است دشوار باشد. این مشکل میتواند در برخی حوزهها مانند پزشکی و حقوقی که نیاز به تفسیر قابلیتها و تصمیمگیریهای مدل دارند، محدودیتهایی ایجاد کند.
مشکل بیشبرازش (Overfitting): شبکههای عصبی CNN در مواجهه با مجموعه دادههای کوچک ممکن است با مشکل بیشبرازش روبهرو شوند. به این معنا که شبکه به طور غیرمنطقی به نمونههای آموزشی خاصی عادت میکند و عملکرد ضعیفی در ارتباط با دادههای جدید و ناشناخته از خود نشان میدهد.
نیاز به دادههای آموزشی برچسبدار: شبکههای عصبی CNN برای آموزش نیاز به دادههای آموزشی برچسبدار دارند. بنابراین، برای هر نمونه از دادهها، برچسب یا باید مشخص شده باشد. جمعآوری و برچسبگذاری دادههای آموزشی ممکن است زمانبر و هزینهبر باشد، به خصوص در حوزههایی که نیاز به تخصیص دقیق برچسبها ضروری است.



بدون دیدگاه