















شبکه عصبی
زمان خواندن: 18 دقیقه
شبکه عصبی حافظه طولانی کوتاه مدت (Long Short-Term Memory) که به اختصار LSTM نامیده میشود قادر به حفظ و بهیادآوری اطلاعات در طول زمان است. LSTM از ایده شبکههای عصبی بازگشتی (Recurrent Neural Networks) الهام گرفته شده است، اما با اضافه کردن ساختارهای خاص واحدهای LSTM، مشکل حفظ اطلاعات در طول زمان را حل میکند. واحدهای LSTM دارای سه دروازه (gate) هستند که توسط شبکه یادگیری مورد استفاده قرار میگیرند. این سه دروازه شامل دروازه فراموشی (forget gate)، دروازه ورودی (input gate) و دروازه خروجی (output gate) هستند. این دروازهها کنترلکنندههایی هستند که تعیین میکنند کدام اطلاعات باید فراموش شوند، کدام اطلاعات جدید وارد شوند و چه مقدار اطلاعات باید برای خروجی استفاده شود. واحدهای LSTM با استفاده از این دروازهها و بازگشت به قبل، قادر به حفظ و بهیادآوری اطلاعات در طول زمان هستند. به عبارت دیگر، نیازی به تنظیم اندازه “حافظه” شبکه نیست و LSTM به صورت خودکار تصمیم میگیرد که کدام اطلاعات را نگه دارد و کدام اطلاعات را فراموش کند. LSTM از مزایای مهمی برخوردار است. از جمله مزایا میتوان به قابلیت حفظ اطلاعات در طول زمان، مقاومت در برابر مشکل vanishing gradient problem که در برخی از شبکههای عصبی بازگشتی وجود دارد و قابلیت استفاده در مسائل پیچیده اشاره کرد.
شبکه عصبی LSTM چیست؟
همانگونه که اشاره کردیم شبکه عصبی LSTM یک نوع شبکه عصبی بازگشتی است که برای پردازش دادههای زمانی طراحی شده است. شبکههای عصبی بازگشتی میتوانند اطلاعات را به صورت دنبالهای پردازش کنند که برای دادههایی مانند متن، صدا و تصویر مفید است. LSTMها به ویژه برای پردازش دادههایی که الگوهای طولانی مدت دارند، مانند متن و صدا، خوب عمل میکند. یک شبکه LSTM از سه گیت فراموشی، گیت و گیت خروجی تشکیل شده است. گیت فراموشی تعیین میکند چه مقدار از اطلاعات قبلی باید نادیده گرفته شوند. گیت ورودی تعیین میکند چه مقدار از اطلاعات جدید باید به حافظه اضافه شود. گیت خروجی تعیین میکند چه مقدار از اطلاعات پردازش شده باید از شبکه خارج شود.
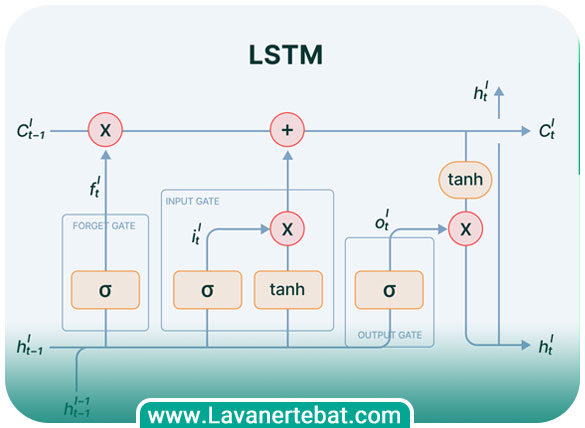
معماری شبکه عصبی lstm
معماری شبکه عصبی LSTM شامل واحدهای LSTM است که به صورت مکرر در طول زمان تکرار میشوند. هر واحد LSTM شامل چندین لایه است که به صورت پشتهای (stacked) قرار میگیرند. در هر لایه، واحدهای LSTM به صورت مکرر تکرار میشوند. همانگونه که پیشتر اشاره شد، اساس کار LSTM مبتنی بر گیتها است. علاوه بر گیتها، هر واحد LSTM شامل یک سلول حافظه (memory cell) است که اطلاعات قبلی را در خود نگه میدارد و امکان حفظ اطلاعات در طول زمان را فراهم میکند. این سلول حافظه با استفاده از دروازهها و ورودیهای جدید، بهروزرسانی میشود و اطلاعات جدید را دریافت میکند. معماری LSTM میتواند به صورت دو جهته (bidirectional) نیز باشد. در این حالت، دو مجموعه از واحدهای LSTM وجود دارد، یک مجموعه برای پردازش دنباله ورودی به صورت معمولی (از چپ به راست) و دیگری برای پردازش دنباله ورودی به صورت برعکس (از راست به چپ). سپس خروجی هر دو مجموعه از واحدهای LSTM با هم ترکیب میشوند. معماری LSTM میتواند در شبکههای عصبی عمیق نیز استفاده شود، به این معنی که چند لایه از واحدهای LSTM به صورت پشتهای قرار میگیرند. هر لایه معمولا واحدهای LSTM بیشتری را در بر میگیرد تا شبکه بتواند اطلاعات پیچیدهتر را یاد بگیرد.
LSTM چگونه کار میکند؟
شبکه عصبی LSTM با استفاده از واحدها و دروازههای خاص خود، قابلیت حفظ و بهیادآوری اطلاعات در طول زمان را به دست میآورد. روند کلی انجام اینکار به شرح زیر است.
ورودی (Input)
دروازه ورودی یکی از سه دروازه اصلی در شبکه عصبی LSTM است که در فرایند تصمیمگیری برای حفظ یا حذف اطلاعات ورودی نقش دارد. دروازه ورودی با استفاده از تابع فعالسازی سیگمویید (sigmoid)، تصمیم میگیرد کدام بخشهای از ورودی باید به حافظه میانمدت (cell state) اضافه شوند. برای درک بهتر، بیایید نحوه عملکرد دروازه ورودی در شبکه LSTM را مرور کنیم.
دروازه ورودی تصمیم میگیرد کدام اطلاعات ورودی باید به حافظه میانمدت اضافه شوند. ورودی شامل بردار ویژگیهای ورودی در یک زمان مشخص است. دروازه ورودی از تابع فعالسازی سیگموئید استفاده میکند. تابع سیگمویید ورودی را به مقادیر بین 0 و 1 تبدیل میکند. این تابع برای محدود کردن مقادیر خروجی بین دو مقدار مورد نظر استفاده میشود. دروازه ورودی با استفاده از تابع سیگمویید، میزان مهمی از ورودی را که باید به حافظه میانمدت ارسال شود، مشخص میکند. دروازه ورودی شامل دو بخش است: وزن ورودی (input gate) و بایاس (bias). وزن ورودی نقشی مشابه وزنهای معمول در شبکههای عصبی دارد. اما بایاس مقدار ثابتی است که به دروازه ورودی اضافه میشود. این دو عنصر مشخص میکنند که چه میزان از ورودی باید به حافظه میانمدت ارسال شود.
پس از محاسبه خروجی دروازه ورودی با استفاده از تابع سیگمویید، خروجی دروازه در هر زمان مشخص میکند کدام بخشهای از ورودی به حافظه میانمدت ارسال شوند. این اطلاعات به حافظه میانمدت ارسال میشوند و در آنجا نگهداری میشوند تا در گامهای بعدی مورد استفاده قرار گیرند. این تابع به عنوان یک “سوییچ” عمل میکند و تصمیم میگیرد که کدام اطلاعات ورودی باید به حافظه میانمدت ارسال شوند (استفاده از مقادیر بالای 0.5) و کدام بخش را باید حذف کند (استفاده از مقادیر زیر 0.5). لازم به توضیح است که دروازه ورودی دارای وزنهای مربوط به هر ویژگی ورودی است. این وزنها نشان میدهند که هر ویژگی چه اهمیتی برای حفظ در حافظه میانمدت دارد.
نقش مهم دیگری که دروازه ورودی دارد ضرب و جمع وزنهای ورودی با ویژگیهای مربوطه است. این عملیات باعث تعیین نقش هر ویژگی ورودی در تصمیمگیری درباره انتقال اطلاعات به حافظه میانمدت میشود. در نهایت خروجی دروازه ورودی مشخص میکند هر ویژگی ورودی به چه میزان به حافظه میانمدت ارسال شود. مقادیر بالای 0.5 نشان دهنده این است که ویژگی باید به حافظه ارسال شود، در حالی که مقادیر زیر 0.5 نشانگر حذف ویژگی از حافظه هستند.
با توجه به توضیحاتی که ارائه کردیم باید بگوییم دروازه ورودی در شبکه عصبی LSTM مسئول تصمیمگیری درباره میزان اطلاعاتی است که وارد حافظه میانمدت (cell state) شود. این دروازه با استفاده از توابع فعالسازی و وزنهای متناسب با ورودی، تصمیم میگیرد که بخشی از ورودی را که حاوی اطلاعات مهم است، به حافظه میانمدت بفرستد و بخش دیگر را که اطلاعات کم اهمیتتری دارد، حذف کند.
دروازه فراموشی (Forget Gate)
دروازه فراموشی (Forget Gate) در شبکه عصبی LSTM نقش مهمی در حفظ و حذف اطلاعات از حافظه میانمدت (cell state) دارد. این دروازه تصمیم میگیرد کدام اطلاعات قبلی در حافظه باید حفظ شوند و کدام بخش را باید فراموش کند.
دروازه فراموشی، ورودی را دریافت میکند که شامل بردار ویژگیهای ورودی در یک زمان مشخص است. در مرحله بعد این دروازه نیز از تابع فعالسازی سیگمویید استفاده میکند. تابع سیگمویید ورودی را به مقادیر بین 0 و 1 تبدیل میکند. این تابع برای محدود کردن مقادیر خروجی بین دو مقدار مورد نظر استفاده میشود. دروازه فراموشی با استفاده از تابع سیگمویید، اهمیت ورودی قبلی که باید در حافظه میانمدت حفظ شود را مشخص میکند. دروازه فراموشی نیز شامل دو بخش است، وزن ورودی (input gate) و بایاس (bias). وزن ورودی نقشی مشابه وزنهای معمول در شبکههای عصبی دارد. اما بایاس مقدار ثابتی است که به دروازه فراموشی اضافه میشود. این دو عنصر مشخص میکنند که چه میزان از ورودی قبلی باید در حافظه میانمدت حفظ شود. پس از محاسبه خروجی دروازه فراموشی با استفاده از تابع سیگمویید، خروجی را در هر زمان مشخص میکند که کدام بخشهای از حافظه میانمدت باید حفظ شوند و کدام بخش باید فراموش شوند. اطلاعات مربوط به بخشهایی که باید حفظ شوند، از طریق دروازه فراموشی به حافظه میانمدت منتقل میشوند و در آنجا نگهداری میشوند تا در گامهای بعدی مورد استفاده قرار گیرند. دروازه فراموشی به صورت یک دروازه سیگموییدی عمل میکند که وظیفه آن انتخاب کردن اطلاعاتی است که باید در حافظه میانمدت نگهداشته شود و اطلاعاتی که باید فراموش شوند. این دروازه با دریافت ورودیهای قبلی از شبکه و وزنهای مربوطه، مقداری بین 0 و 1 را تولید میکند که نشاندهنده میزان فراموشی هر بخش از حافظه میانمدت است.
دروازه خروجی (output gate)
دروازه خروجی در LSTM مسئول کنترل مقدار اطلاعاتی است که از شبکه خارج می شود. این دروازه از دو ورودی تشکیل شده است. خروجی گیت فراموشی که تعیین میکند چه مقدار از اطلاعات قبلی باید در حافظه باقی بماند. خروجی سلول تعیین میکند چه مقدار از اطلاعات پردازش شده باید از شبکه خارج شود. خروجی دروازه خروجی به عنوان یک تابع خطی از این دو ورودی محاسبه می شود:
output_gate = sigmoid(W_out [forget_gate, cell_output])
که در آن W_out وزنهای دروازه خروجی هستند و [forget_gate, cell_output] ورودیهای دروازه خروجی هستند. خروجی دروازه خروجی سپس با سلول ضرب میشود تا مقدار اطلاعاتی که از شبکه خارج میشود محاسبه شود:
output = output_gate cell_state
در دستور بالا output مقدار اطلاعاتی است که از شبکه خارج میشود، در حالی که cell_state مقدار اطلاعاتی است که در سلول ذخیره شده است. خروجی دروازه خروجی میتواند مقادیری بین 0 و 1 داشته باشد. مقادیر نزدیک به 0 نشان میدهد که مقدار کمی از اطلاعات از شبکه خارج میشود. مقادیر نزدیک به 1 نشان میدهد که مقدار زیادی از اطلاعات از شبکه خارج میشود. دروازه خروجی میتواند برای کنترل جریان اطلاعات در شبکه LSTM استفاده شود. به عنوان مثال، میتوان از آن برای کنترل اینکه چه مقدار از اطلاعات قبلی برای پردازش بعدی در دسترس است استفاده کرد. همچنین، میتوان از آن برای کنترل اینکه چه مقدار از اطلاعات پردازش شده به عنوان خروجی شبکه ارسال میشود استفاده کرد.
لازم به توضیح است که میتوان از دروازه خروجی برای کنترل اینکه چه مقدار از اطلاعات قبلی برای پردازش بعدی در دسترس است استفاده کرد. به عنوان مثال، میتوان از آن برای اطمینان از اینکه فقط اطلاعات مرتبط با وظیفه فعلی در دسترس است استفاده کرد. همچنین، میتوان از دروازه خروجی برای کنترل اینکه چه مقدار از اطلاعات پردازش شده به عنوان خروجی شبکه ارسال میشود استفاده کرد. به عنوان مثال، میتوان از آن برای اطمینان از اینکه خروجی شبکه به اندازه کافی دقیق است استفاده کرد.

چگونه میتوانیم شبکه عصبی LSTM را برای مسایل ترجمه ماشینی استفاده کنیم؟
اگر در نظر دارید از شبکه عصبی LSTM برای مساله ترجمه ماشینی، روند کلی انجام اینکار به این صورت است که ابتدا باید فرآیند جمعآوری دادهها را انجام دهید. به بیان دقیقتر، ابتدا، نیاز دارید تا دادههای آموزشی که شامل جفتهای جملههای مبدا و مقصد هستند را جمعآوری کنید. این جفتها باید به صورت یک جفت به همراه برچسب مناسب (برچسب ترجمه شده) در دسترس باشند. میتوانید از منابع عمومی مانند مجموعه دادههای ترجمه ماشینی مانند WMT و IWSLT استفاده کنید. مرحله بعد نوبت به پیشپردازش دادهها میرسد. برای استفاده از دادهها در شبکه عصبی، به پیشپردازش دادهها دارید. این فرآیند شامل عملیاتی مانند جدا کردن جملات به کلمات، ساخت واژهنامه (vocab) با استفاده از کلمات در دادههای آموزشی، تبدیل کلمات به بردارهای عددی (تعبیه کلمه) و تبدیل جملات به دنبالههایی از این بردارها میشود. مرحله بعد نوبت به ساخت مدل شبکه عصبی LSTM میرسد. اکنون باید مدل شبکه عصبی LSTM را بسازید. شما میتوانید از کتابخانههای موجود مانند TensorFlow یا PyTorch استفاده کنید. شبکه عصبی LSTM حداقل شامل دو لایه هستند که یک لایه ورودی و یک لایه خروجی است. همچنین، میتوانید از لایههای بازگشتی (recurrent layer) مانند LSTM یا GRU استفاده کنید تا وابستگیهای زمانی را در نظر بگیرید. در ادامه نوبت به آموزش مدل میرسد. در این مرحله، مدل شبکه عصبی را بر روی دادههای آموزشی آموزش میدهید. به عنوان مثال، با استفاده از الگوریتم پسانتشار خطا (backpropagation) و بهینهسازی مانند Adam یا RMSprop، وزنها و پارامترهای مدل را بهروزرسانی میکنید تا خطا در پیشبینی ترجمه کاهش یابد. پس از آموزش، میتوانید مدل را بر روی دادههای آزمون ارزیابی کنید. با استفاده از شبکه عصبی آموزش دیده، جملههای مبدا را به عنوان ورودی به مدل میدهید و جملههای مقصد ترجمه شده را که برچسبهای صحیح هستند، با استفاده از مدل پیشبینی میکنید. سپس میتوانید از معیارهای ارزیابی مانند BLEU، METEOR، یا TER برای ارزیابی کیفیت ترجمه استفاده کنید. پس از آموزش و ارزیابی مدل، میتوانید از آن برای ترجمه جملات جدید استفاده کنید. با قرار دادن جمله مبدا به عنوان ورودی به مدل، میتوانید جمله مقصد ترجمه شده را با استفاده از مدل پیشبینی کنید.
این فرایند را میتوانید با استفاده از کتابخانههای موجود در پایتون مانند TensorFlow یا PyTorch پیادهسازی کنید. همچنین، اگر میخواهید یک راه حل سریعتر و سادهتر داشته باشید، میتوانید از کتابخانههای موجود برای ترجمه ماشینی مانند Google Translate API یا Microsoft Translator API استفاده کنید.
کاربردهای شبکه عصبی LSTM
شبکه عصبی LSTM برای حل مسایل متنوع در حوزه هوش مصنوعی و پردازش زبان طبیعی به شکل گستردهای استفاده میشود. اولین کاربرد آن که در پاراگراف قبل به آن اشاره کردیم در ارتباط با ترجمه ماشینی است. LSTM به خاطر توانایی خود در مدلسازی ساختار جملات و تعامل بین کلمات، در ترجمه ماشینی موفق عمل کرده است. با استفاده از LSTM، میتوان ماشین را آموزش داد تا جملات را به صورت دقیق ترجمه کند. مورد بعد در ارتباط با تشخیص عناصر معنایی است. از آنجا که LSTM توانایی حفظ اطلاعات در طول زمان را دارد، میتواند در تشخیص عناصر معنایی در جملات مفید باشد. به طور مثال، در تشخیص افعال، اسامی، صفتها و مفاهیم دیگر، LSTM میتواند دقت بالایی داشته باشد. این شبکه در ارتباط با تولید خودکار متن نیز کاربرد دارد و قادر به تولید دنبالههای متنی قابل استفاده است. برای مثال، میتوان از LSTM در تولید شعر، داستان و گزارشات متنی استفاده کرد. LSTM میتواند در تشخیص و تحلیل احساسات متنی نیز مفید واقع شود. با استفاده از LSTM، میتوان مدلهایی را آموزش داد که بتوانند احساسات موجود در نظرات کاربران را تشخیص دهند. کاربرد جالب توجه دیگر این فناوری در زمینه تولید آهنگ است. LSTM میتواند در ساخت موسیقی نیز کاربرد داشته باشد تا بتواند قطعات موسیقی جدید و آهنگهای زیبایی تولدی کند. یکی دیگر از کاربردهای مهم این فناوری در ارتباط با پیشبینی سریهای زمانی است. LSTM به دلیل توانایی خود در مدلسازی زمانی در پیشبینی سریهای زمانی مانند قیمتهای بازار سهام، دمای هوا، میزان فروش و غیره مورد استفاده قرار میگیرد. با استفاده از LSTM، میتوان ترندها و الگوهای موجود در دادههای زمانی را تشخیص داد و پیشبینی کرد. موارد یاد شده تنها چند مورد از کاربردهای شبکه عصبی LSTM هستند. این شبکه به دلیل قابلیت حفظ اطلاعات در طول زمان و قدرت مدلسازی ساختار جملات و تعامل بین عناصر متن، در حوزههای مختلفی از پردازش زبان طبیعی و هوش مصنوعی استفاده میشود.
مقایسه LSTM و RNN در یک نگاه
شبکه عصبی LSTM و شبکه عصبی بازگشتی (RNN) دو نوع از شبکههای عصبی با حافظه هستند که برای پردازش دادههای دنبالهای مورد استفاده قرار میگیرند. هر دو این شبکهها قابلیت حفظ اطلاعات در طول زمان را دارند، اما با توجه به ساختار و عملکرد آنها، تفاوتهای مهمی بین LSTM و RNN وجود دارد. در زیر به برخی از این تفاوتها اشاره میکنم:
- مشکل محوشدگی گرادیان (Vanishing Gradient Problem): در شبکههای عصبی بازگشتی سنتی، مشکلی به نام مشکل محوشدگی گرادیان وجود دارد که به معنای این است که در هنگام آموزش، گرادیانها به سمت لایههای اولیه میل میکنند و اطلاعات زمانی دورتر به طور محسوسی فراموش میشوند. این مشکل باعث میشود که شبکه عصبی نتواند به درستی اطلاعات زمانی طولانی را در نظر بگیرد. در LSTM، با استفاده از واحدهای حافظه خاصی به نام سلول حافظه، این مشکل برطرف میشود و شبکه قادر است اطلاعات طولانیمدت را به خوبی حفظ کند.
- قابلیت حفظ وابستگی طولانیمدت: به دلیل وجود سلول حافظه، LSTM قادر است وابستگیهای طولانیمدت در دادههای دنبالهای را به خوبی حفظ کند. این قابلیت به LSTM اجازه میدهد تا اطلاعات زمانی از گذشته را در هنگام پیشبینی و تولید دنبالههای آینده به کار گیرد. در RNN سنتی، به دلیل مشکل مشکل محوشدگی گرادیان، قدرت حفظ وابستگیهای طولانیمدت محدودتر است.
- توانایی کار با دنبالههای طولانی: LSTM به خاطر ساختار خود که از سلول حافظه تشکیل شده است، قادر است با دنبالههای طولانیتر کار کند. در RNN سنتی، با افزایش طول دنباله، مشکل مشکل محوشدگی گرادیان شدیدتر میشود و دقت شبکه کاهش مییابد.
- توانایی کار با دادههای جدولی: LSTM بر خلاف RNN که برای دادههای دنبالهای بهینهسازی شده است، قادر است با دادههای جدولی نیز کار کند. با استفاده از شبکه LSTM، میتوان دادههای جدولی را مدل کرده و وابستگیهای طولانیمدت در این دادهها را نیز حفظ کرد.
به طور خلاصه، LSTM با وجود سلول حافظه خود توانایی حل مشکل مشکل محوشدگی گرادیان را دارد و قابلیت حفظ وابستگیهای طولانیمدت را در دادههای دنبالهای دارد. این ویژگیها باعث میشود که LSTM در بسیاری از کاربردها که نیاز به مدلسازی دنبالهها و حفظ اطلاعات طولانیمدت دارند، موثرتر از RNN سنتی باشد.
LSTM چه مزایایی در اختیار ما قرار میدهد؟
این شبکهها برخلاف شبکههای عصبی بازگشتی سنتی، دارای مزایای منحصر به فردی هستند. اولین مورد حفظ اطلاعات به شکل طولانیمدت است. با وجود سلول حافظه LSTM، این شبکهها قادرند اطلاعات را برای مدت زمان طولانی حفظ کنند. این ویژگی به LSTM اجازه میدهد تا وابستگیهای طولانیمدت در دادههای دنبالهای را مورد استفاده قرار داده و در مدلسازی و پیشبینی دقیقتر از آنها استفاده کند. با استفاده از سلول حافظه در LSTM، محوشدگی اطلاعات برطرف میشود. در کل، LSTM با وجود سلول حافظه و ویژگیهای خاص خود، قابلیت حفظ اطلاعات طولانیمدت و حل مشکل محوشدگی گرادیان را دارد که این ویژگیها باعث میشود LSTM در بسیاری از کاربردها که نیاز به مدلسازی دنبالهها و حفظ اطلاعات طولانیمدت دارند، موثرتر از دیگر شبکههای عصبی بازگشتی باشد.
LSTM چه معایبی دارد؟
شبکههای عصبی LSTM بهرغم مزایایی که دارند، معایب نیز دارند. اولین مورد پیچیدگی مدل است. شبکههای LSTM نسبت به شبکههای عصبی دیگر پیچیدهتر هستند. این نوع شبکهها نیازمند تنظیم پارامترهای مختلفی مانند اندازه حافظه، نرخ یادگیری و غیره هستند. تنظیم این پارامترهای کنترلی ممکن است مشکل باشد و نیاز به تجربه و تنظیمات مکرر برای دستیابی به عملکرد بهینه ضروری باشد. با توجه به وجود تعداد زیادی سلول در شبکه و استفاده از حافظه طولانیمدت، شبکه LSTM مقدار زیادی حافظه را مصرف میکند. این هزینه ممکن است از نظر منابع مورد نیاز برای آموزش و اجرای مدل بالا باشد و در صورت محدودیت منابع یا ظرفیت محاسباتی، باعث بروز مشکلاتی شود.
به دلیل پیچیدگی و مصرف حافظه بالا، آموزش شبکههای LSTM ممکن است زمان طولانیتری نسبت به شبکههای عصبی دیگر داشته باشد. در برخی موارد که به روزرسانیهای سریع ضروری است یا زمان آموزش محدود است، مشکل فوق به چالش بزرگی تبدیل میشود. شبکههای LSTM نیاز به تنظیم دقیق دارند تا عملکرد خوبی داشته باشند. در صورت عدم تنظیم صحیح پارامترها و تنظیمات، مدل ممکن است با مشکلاتی مانند انفجار گرادیان (exploding gradients) یا محو شدگی گرادیان (vanishing gradients) یا عملکرد ضعیف روبهرو شود. یافتن تنظیمات بهینه در برخی موارد ممکن است دشوار باشد و به تجربه و دانش گسترده در طراحی مدل نیاز داشته باشد. بهرغم معایب فوق، شبکههای LSTM هنوز ابزار قدرتمندی برای مدلسازی مسائل مرتبط با دادههای زمانی و وابستگیهای طولانیمدت هستند.
بخوانید: استاندارد کابل کشی TIA-568



بدون دیدگاه