















شبکه عصبی پرسپترون
زمان خواندن: 19 دقیقه
شبکه عصبی پرسپترون (Perceptron Neural Network) یکی از اولین و سادهترین مدلهای شبکههای عصبی است. این مدل توسط فرانک روزنبلات در دهه 1950 معرفی شد و به عنوان مبنای اصلی برای توسعه شبکههای عصبی پیچیدهتر مورد استفاده قرار گرفت. شبکه عصبی پرسپترون به صورت یک لایه از نورونها (یا واحدهای پردازش) ساخته میشود. هر نورون ورودیهای خود را با وزنهای مشخصی دریافت کرده و آنها را با یک تابع فعالسازی خطی (مانند تابع آمیخته) ترکیب میکند. سپس خروجی حاصل را از طریق تابع فعالسازی غیرخطی (مانند تابع سیگموید یا تابع ReLU) تبدیل میکند. این خروجی نهایی به عنوان خروجی شبکه عصبی استفاده میشود.
شبکه عصبی پرسپترون در اصل به عنوان یک طبقهکننده دودویی استفاده میشود، به این معنی که میتواند ورودیهای مختلف را به دو دستهی متفاوت تقسیم کند. برای آموزش شبکه، از الگوریتم دستهبندی گرادیان کاهشی (Gradient Descent) استفاده میشود تا وزنها به طور مداوم بهینهسازی شوند و شبکه به درستی عمل کند. اگرچه شبکه عصبی پرسپترون ساده و محدود به یک لایه است، اما از آن به عنوان پایهای برای ساختارهای شبکههای عصبی پیچیدهتر استفاده میشود. با ترکیب چندین لایه از پرسپترونها و استفاده از توابع غیرخطی و پیچیدهتر برای تبدیل ورودیها، میتوان ساختارهای عمیقتر و پیچیدهتری از شبکههای عصبی را ایجاد کرد.
ساختار پرسپترون (Perceptron) چیست؟
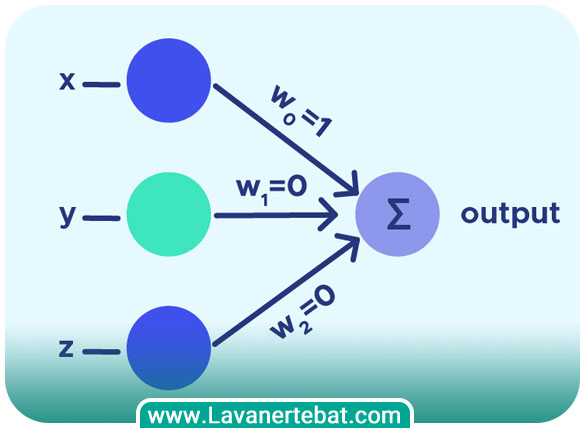
ساختار پرسپترون (Perceptron) از دو عنصر اصلی تشکیل شده است: ورودیها و وزنها. هر پرسپترون ورودیهای خود را با وزنها ضرب میکند و سپس این مقادیر را جمع میکند. نتیجهی این جمع به عنوان ورودی تابع فعالسازی استفاده میشود. به طور کلی، ساختار پرسپترون به صورت زیر است:
ورودیها:
هر پرسپترون ورودیهای خود را دریافت میکند. این ورودیها میتوانند اعداد عددی یا مقادیر دودویی باشند. عموماً ورودیها را با x۱، x۲، x۳ و غیره نمایش میدهند.
وزنها:
هر ورودی دارای وزنی است که نشان دهنده اهمیت آن ورودی در نتیجهی نهایی پرسپترون است. وزنها معمولا با w۱، w۲، w۳ و غیره نمایش داده میشوند. هر ورودی با وزن متناظر خود ضرب میشود.
تابع فعالسازی:
مقدار حاصل از جمع وزنها و ورودیها به عنوان ورودی به یک تابع فعالسازی غیرخطی میرود. این تابع ممکن است تابع سیگموید، تابع آمیخته، تابع ReLU و غیره باشد. تابع فعالسازی تعیین کنندهی خروجی پرسپترون است.
خروجی:
خروجی پرسپترون نتیجه تابع فعالسازی است. این خروجی میتواند یک عدد عددی یا یک مقدار دودویی (مثلا 0 و 1) باشد، بسته به نوع مسالهای که پرسپترون برای آن طراحی شده است.
ساختار پرسپترون بسیار ساده است و برای مسایل ساده و خطی مناسب است. اما برای حل مسایل پیچیدهتر، ممکن است نیاز به استفاده از شبکههای عصبی چندلایه (MLP) باشد که از چندین پرسپترون به صورت لایههای متعدد تشکیل شدهاند.

نحوهی کار پرسپترون چگونه است؟
نحوه کار پرسپترون به این صورت است که ابتدا مقداردهی اولیه وزنها انجام میشود. وزنها به طور تصادفی یا با استفاده از روشهای مقداردهی مشخصی مانند صفر یا اعداد کوچک تصادفی مقداردهی میشوند. در ادامه نوبت به محاسبه خروجی میرسد. پرسپترون ورودیهای خود را دریافت کرده و با وزنها ضرب میکند. سپس، جمع این مقادیر را محاسبه کرده و نتیجهی حاصل را به عنوان ورودی به تابع فعالسازی میفرستد. تابع فعالسازی نتیجهی حاصل را تبدیل میکند و به عنوان خروجی پرسپترون ارائه میدهد. خروجی پرسپترون با خروجی مورد انتظار مقایسه میشود و خطای محاسبه میشود. این خطا معمولا با استفاده از تابع خطا مانند میانگین مربعات خطا (MSE) محاسبه میشود. با استفاده از الگوریتم دستهبندی گرادیان کاهشی (Gradient Descent)، وزنها به طور مداوم به روزرسانی میشوند تا خطا کاهش یابد. این بهروزرسانی وزنها بر اساس مقدار خطا و نرخ یادگیری (learning rate) صورت میگیرد. مراحل فوق به غیر از مقداردهی اولیه تکرار میشوند تا زمانی که خطای پرسپترون به حد مطلوبی کاهش یابد یا تعداد مشخصی از تکرارها انجام شود.
پس از آموزش پرسپترون، با ورودی جدید، پرسپترون مقدار پیشبینی شده را تولید میکند. این مقدار میتواند یک عدد عددی یا یک مقدار دودویی باشد، بسته به نوع مسالهای که پرسپترون برای آن آموزش داده شده است.
این مراحل به طور تکراری برای هر داده آموزشی انجام میشوند تا وزنها بهینه شده و پرسپترون به درستی کار کند. البته، اگر دادههای آموزشی خطی قابل جداسازی نباشند، پرسپترون نمیتواند به صورت مطلوب عمل کند و حتی ممکن است در حلقه بینهایت گرفتار شود. در چنین شرایطی از شبکههای عصبی چندلایه (MLP) استفاده میشود که شامل چندین لایه پرسپترون است و قادر به حل مسایل پیچیدهتر است.
نمونهای از تابع فعالسازی غیرخطی برای پرسپترون
تابع فعالسازی غیرخطی یک عنصر بسیار مهم در پرسپترون و شبکههای عصبی است. یکی از توابع فعالسازی غیرخطی معروف به تابع سیگموید (Sigmoid) است. تابع سیگموید تبدیل ورودی خطی را به مقداری بین 0 و 1 نگاشت میکند. فرمول تابع سیگموید به صورت زیر است:
f(x) = 1 / (1 + exp(-x))
در این فرمول، x نشان دهنده ورودی پرسپترون است و f(x) نشان دهنده خروجی تابع سیگموید است. قابل ذکر است که تابع سیگموید قابلیت تبدیل ورودی خطی را به خروجی غیرخطی دارد و به عنوان یک تابع فعالسازی مشتقپذیر محسوب میشود. تابع سیگموید معمولا در پرسپترونها و شبکههای عصبی استفاده میشود، به خصوص در مسایلی که خروجی به صورت احتمالی بین 0 و 1 مورد نیاز است، مانند مسایل دستهبندی دودویی.
چه نوع مسایلی برای استفاده از شبکههای عصبی چندلایه مناسب هستند؟
شبکههای عصبی چندلایه (MLP) به دلیل قدرت آنها در تعاملات غیرخطی، برای حل مسایل پیچیده و متنوع مناسب هستند. این شبکهها برای مسایلی که خروجیها وابسته به ویژگیهای پیچیده و ترکیبی از ورودیها هستند، بسیار مفید هستند. مسایلی که امکان حل آنها با استفاده از شبکههای عصبی چندلایه وجود دارند به شرح زیر هستند:
دستهبندی چنددستهای: شبکههای عصبی چندلایه میتوانند در مسایل دستهبندی چنددستهای مانند تشخیص تصویر و یا تشخیص گفتار مورد استفاده قرار بگیرند.
تشخیص الگو: مسایلی مانند تشخیص چهره، تشخیص نوشتهها، تشخیص سیگنالها و الگوهای پیچیده دیگر، قابلیت استفاده از شبکههای عصبی چندلایه را دارند.
پیشبینی و تحلیل سری زمانی: شبکههای عصبی چندلایه برای پیشبینی و تحلیل سریهای زمانی مانند پیشبینی قیمت سهام، پیشبینی آب و هوا، پیشبینی ترافیک و غیره مورد استفاده قرار میگیرند.
تشخیص الگوی صدا: شبکههای عصبی چندلایه در مسایل تشخیص الگوی صدا و تشخیص سبک صدا مفید هستند.
پردازش زبان طبیعی: در حوزه پردازش زبان طبیعی، شبکههای عصبی چندلایه برای مسایل مانند ترجمه ماشینی، تولید متن و تحلیل احساسات مورد استفاده قرار میگیرند.
وزنها به چه دلیل در پرسپترون استفاده میشوند؟
وزنها در پرسپترون برای تعیین اهمیت و تاثیر ورودیها در فرآیند تصمیمگیری مورد استفاده قرار میگیرند. هر ورودی به پرسپترون با یک وزن متناظر ضرب میشود و مجموع این ضربها در نهایت به تابع فعالسازی اعمال میشود تا خروجی پرسپترون تولید شود.
به طور کلی، وزنها نشان میدهند که هر ورودی چقدر برای پرسپترون مهم است. با تنظیم مقادیر وزنها، میتوان تاثیر ورودیها را تنظیم کرده و به پرسپترون یاد بدهیم که با توجه به اهمیت ورودیها، تصمیمگیری کند. هر وزن مرتبط با اتصالات بین نورونها است. وزن مشخص کننده نقش هر ورودی در خروجی نورون مقصد است. وزنها مقادیر قابل تنظیم هستند و در فرآیند آموزش شبکه عصبی بهروزرسانی میشوند. این حرف به معنی این است که شبکه عصبی با تغییر وزنها، بهبود در عملکرد و توانایی تصمیمگیری دارد.
با تنظیم و بهینهسازی وزنها، پرسپترون قادر است الگوهای پیچیده را تشخیص دهد و در مسایل دستهبندی، بهبود در دقت و عملکرد کلی داشته باشد. وزنها میتوانند به عنوان پارامترهای قابل یادگیری در فرآیند آموزش شبکه عصبی محسوب شوند و با تغییر آنها، شبکه قادر به تطبیق و تعلیم بهتر با دادههای ورودی میشود. در فرآیند آموزش شبکه عصبی، مقادیر وزنها بهروزرسانی میشوند تا شبکه بهبود یابد و بهترین عملکرد را از خود نشان دهد. روشهای مختلفی برای بهروزرسانی وزنها وجود دارد، اما یکی از روشهای رایج و مهم برای بهبود عملکرد شبکه، الگوریتم بهینهسازی معروف به “گرادیان کاهشی” (Gradient Descent) است. روند کار الگوریتم فوق به صورت زیر است:
محاسبه خطا:
ابتدا خطای شبکه بر اساس خروجی تولیدی و خروجی مورد انتظار محاسبه میشود. این خطا معمولا با استفاده از یک تابع هدف (تابع هزینه) محاسبه میشود. مثالی از تابع هدف میتواند میانگین مربعات خطا (Mean Squared Error) باشد.
محاسبه گرادیان:
سپس، گرادیان تابع هدف نسبت به وزنها محاسبه میشود. این گرادیان نشان میدهد که با تغییر وزنها به چه اندازه خطا کاهش مییابد یا افزایش مییابد.
بهروزرسانی وزنها:
در این مرحله، وزنها با استفاده از گرادیان کاهشی بهروزرسانی میشوند. روشهای مختلفی برای بهروزرسانی وزنها وجود دارد، اما یک روش رایج استفاده از نرخ یادگیری (Learning Rate) است. نرخ یادگیری مقدار کوچکی است که تعیین میکند چقدر وزنها در هر مرحله بهروزرسانی میشوند.
تکرار مراحل بالا:
این مراحل برای تمام دادههای آموزش تکرار میشوند تا شبکه بهترین مقادیر وزنها را بیابد. این فرآیند به عنوان یک “اپوک” شناخته میشود.
مراحل فوق فقط یک روش ساده از بهروزرسانی وزنها بر اساس الگوریتم گرادیان کاهشی بود. در عمل، ممکن است از نسخههای پیشرفتهتر و بهینهتری از این الگوریتم مانند گرادیان کاهشی تطبیقی (Stochastic Gradient Descent)، گرادیان کاهشی تطبیقی بازگشتی (Recurrent Neural Networks) و الگوریتمهای بهینهسازی مبتنی بر معیارهای دیگر استفاده میشود. این الگوریتمها به صورت متفاوتی از گرادیان هزینه استفاده کرده و مقادیر وزنها را بهروزرسانی میکنند. هدف این الگوریتمها همچنین از بدون گیر کردن در نقاط محلی بودن و پیدا کردن بهینه محلی و گرچهها است. به طور خلاصه، مقادیر وزنها در فرآیند آموزش شبکه عصبی بهروزرسانی میشوند تا شبکه بهبود یابد و خطا را کاهش دهد. الگوریتم گرادیان کاهشی و نسخههای بهینهتر آن، ابزارهای اصلی برای بهروزرسانی وزنها در فرآیند آموزش شبکه عصبی هستند.
چرا از مقدار ثابت بایاس استفاده میکنیم؟
مقدار ثابت بایاس (bias) در شبکههای عصبی برای افزایش انعطافپذیری و قدرت تصمیمگیری شبکه استفاده میشود. بایاس در واقع یک ورودی ثابت است که به هر نورون اضافه میشود و تاثیری در خروجی نورون دارد. استفاده از بایاس به دو دلیل اصلی منطقی است:
تخمین تفاوت مبدا:
با استفاده از بایاس، شبکه عصبی قادر است تفاوتی را بین خروجی مطلوب و خروجی واقعی که ناشی از اختلاف مبدا (مثلا نقطه شروع صفر) است، تخمین بزند. برای مثال، در یک نورون ساده با وزنهای صفر، اگر بایاس صفر نباشد، نورون قادر است خروجی غیرصفری را تولید کند. این امر به شبکه کمک میکند تا الگوها و تفاوتهای مختلف را بهبود بخشد.
تعدیل نقش تاثیر ورودیها:
بایاس به شبکه اجازه میدهد تا تاثیر ورودیها را تعدیل کند. با تنظیم مقدار بایاس، شبکه میتواند تاثیر ورودیها را به طور پویا تغییر دهد و بهترین مقدار بین ورودیها را برای تصمیمگیری پیدا کند. بنابراین، بایاس به شبکه امکان میدهد تا خودش را به بهترین نقطه تعدیل کند و با توجه به اهمیت و تاثیر هر ورودی، تصمیمگیری کند.
آیا مقدار بایاس برای هر نورون در شبکه عصبی یکسان است؟
پاسخ منفی است. مقدار بایاس میتواند برای هر نورون در شبکه عصبی متفاوت باشد. در واقع، مقدار بایاس برای هر نورون بهعنوان یک پارامتر قابل یادگیری در نظر گرفته میشود و میتواند در فرآیند آموزش تغییر کند. وزنها و بایاسها در شبکه عصبی برای تعیین خروجی نورونها مهم هستند. هر نورون دارای یک بایاس است که به خروجی آن اضافه میشود. این بایاس به عنوان عامل تغییر مبدا و تعدیل تاثیر ورودیها در نورون عمل میکند. در عمل، مقدار بایاس برای هر نورون بهطور تصادفی اولیه تعیین میشود و در ادامه فرآیند آموزش، با استفاده از الگوریتم بهینهسازی (مانند گرادیان کاهشی)، بهبود مییابد. هدف این بهینهسازی، پیدا کردن مقدار بهینه برای بایاس هر نورون است که بهبود عملکرد کلی شبکه را داشته باشد. بنابراین، مقدار بایاس میتواند برای هر نورون متفاوت باشد و در فرآیند آموزش، بهطور متناسب با دادهها و هدف شبکه تغییر کند تا بهترین مقدار برای عملکرد شبکه را پیدا کند.
تابع فعالساز چه کاری انجام میدهد؟
تابع فعالساز (activation function) یک عنصر کلیدی در شبکههای عصبی است و وظیفه اصلی آن تعیین خروجی نورون بر اساس مجموع وزنها و ورودیهای آن است. تابع فعالساز به طور غیرخطی و غیرترتیبی، نقشی برای تبدیل وزنها و ورودیها به خروجی نورون ایفا میکند. تابع فعالساز میتواند انواع مختلفی داشته باشد، از جمله:
تابع سیگموید (Sigmoid):
این تابع یک منحنی S-شکل است که ورودی را به مقداری بین 0 و 1 تبدیل میکند. این تابع برای محدود کردن خروجی بین مقادیر ثابت استفاده میشود و در مدلهای قدیمیتر شبکههای عصبی مورد استفاده قرار میگیرد.
تابع تانژانت هیپربولیک (Hyperbolic Tangent):
این تابع نیز مشابه تابع سیگموید است، با این تفاوت که خروجی آن بین -1 و 1 قرار دارد. ما از تابع تانژانت هیپربولیک به این دلیل استفاده میکنیم تا مقادیر منفی را به دست آوریم و برای مسایلی که دامنه خروجی منفی دارند از آن استفاده کنیم.
تابع (Rectified Linear Unit):
این تابع خروجی را برابر با صفر برای ورودیهای منفی قرار میدهد و ورودیهای مثبت را بدون تغییر بازمیگرداند. تابع ReLU برای حذف خطینشدن و افزایش توانایی شبکه در یادگیری الگوهای پیچیده مفید است و در بسیاری از معماریهای شبکه عصبی مدرن استفاده میشود.
تابع فعالساز بستگی به مساله و معماری شبکه ممکن است متفاوت باشد. انتخاب صحیح تابع فعالساز در شبکه عصبی میتواند بر عملکرد و دقت شبکه تاثیر گذار باشد و در بسیاری از موارد، تعیین کنندهای برای موفقیت آموزش مدل است.

چرا پرسپترون را جزوی از شبکه عصبی مینامیم؟
پرسپترون، به عنوان یک واحد پردازشگر ساده، به تنهایی میتواند به عنوان یک مدل ماشینی عمل کند. اما وقتی چندین پرسپترون به هم متصل شده و به یکدیگر ارتباط میدهند، یک شبکه عصبی حاصل میشود. شبکههای عصبی از تعداد زیادی نورون و ارتباطات بین آنها تشکیل میشوند. پرسپترونها در واقع نمایندگان سادهترین واحدهای عصبی در یک شبکه عصبی هستند. هر پرسپترون ورودیهای خود را از پیش تعیین شده میگیرد، آنها را با وزنهای مربوطه ترکیب میکند و خروجی را با توجه به تابع فعالساز محاسبه میکند.
با متصل کردن چندین پرسپترون به یکدیگر و ایجاد ارتباطات بین آنها، میتوانیم شبکههای عصبی پیچیدهتر و قادر به انجام عملیات پیچیدهتر را بسازیم. ارتباطات بین پرسپترونها میتوانند به صورت لایه به لایه (مانند شبکههای عصبی پرسپترون چندلایه) یا به صورت پراکندهتر (مانند شبکههای عصبی بازگشتی) باشند. بنابراین، پرسپترون را به عنوان یک واحد ساده در شبکههای عصبی میتوان نگاه کرد. شبکههای عصبی با ترکیب و اتصال پرسپترونها به یکدیگر قدرت بیشتری در حل مسایل پیچیده مانند تشخیص الگو، دستهبندی تصاویر، ترجمه ماشینی و غیره دارند.
مثالی ملموس از کاربرد شبکههای عصبی پیچیده در دنیای واقعی
به طور مثال، یک کاربرد واقعی از شبکههای عصبی پیچیده میتواند در حوزه تشخیص تصویر و دستهبندی آنها باشد. با پیشرفت فناوری و افزایش توانایی شبکههای عصبی، این کاربرد در بسیاری از زمینهها مانند خودرو، پزشکی، امنیت، شبکههای اجتماعی و غیره استفاده میشود. به عنوان مثال، فرض کنید شما یک شرکت بزرگ خودروسازی دارید و قصد دارید از تصاویر ماشینها تشخیص دهید که آیا خودروی تولید شده توسط شما در تصویر وجود دارد یا خیر. برای این منظور، میتوانید یک شبکه عصبی پیچیده با استفاده از معماری شبکههای عصبی عمیق (Deep Neural Networks) طراحی کنید.
ابتدا شبکه عصبی را با تصاویر آموزش میدهید. در این مرحله، شبکه با استفاده از تصاویری که خودروی تولید شده توسط شما در آنها وجود دارد (برچسبگذاری شده) و تصاویری که خودروی شما در آنها حضور ندارد (بدون برچسب)، آموزش میبیند. شبکه با تحلیل ویژگیهای مختلف در تصاویر، یاد میگیرد که چگونه خودروی شما را از تصاویر دیگر تشخیص دهد. پس از آموزش، شبکه عصبی آماده استفاده است. شما میتوانید تصاویر جدیدی که شامل خودروی شما هستند به شبکه ورودی دهید. شبکه با استفاده از الگوریتمهای پیچیدهای مانند پیامدهای عمیق (Deep Features) و استفاده از لایههای پیچیدهتر در شبکه، تصویر را تحلیل کرده و تشخیص میدهد که آیا خودروی شما در تصویر وجود دارد یا خیر.
لمس سطح داغ در شبکه عصبی و پرسپترون (Perceptron)
به طور کلی، میتوان از شبکههای عصبی برای تشخیص و پیشبینی مواردی مانند لمس سطح داغ استفاده کرد. اما برای توضیح کاملتر، بهتر است از یک مثال سادهتر استفاده کنیم. فرض کنید که شما قصد دارید یک سیستم را طراحی کنید که قادر به تشخیص و هشدار دادن در مورد لمس سطحهای داغ باشد. در این حالت، میتوانید از یک پرسپترون به عنوان واحد پردازشگری اولیه استفاده کنید.
پرسپترون در این مثال میتواند ورودیهایی مانند دما و فشار را دریافت کند. بر اساس ورودیهای دریافتی، پرسپترون با استفاده از وزنهای مربوطه و تابع فعالسازی، تصمیم میگیرد که آیا سطح لمسی داغ است یا خیر. به طور مثال، اگر دما و فشار ورودی بیشتر از مقادیر آستانهای تعیین شده باشد، پرسپترون میتواند خروجی یک (داغ) را تولید کند، در غیر این صورت خروجی صفر (سرد) خواهد بود.
اکنون، اگر بخواهیم به جای استفاده از یک پرسپترون، یک شبکه عصبی پیچیدهتر را برای تشخیص لمس سطح داغ استفاده کنیم، میتوانیم به جای یک پرسپترون، چندین پرسپترون را به صورت متوالی یا موازی و با ارتباطات بین آنها به کار ببریم. به عنوان مثال، هر پرسپترون میتواند برای تشخیص ویژگیهای خاصی از لمس سطح داغ مانند دما، فشار و سرعت استفاده شود. سپس، خروجی هر پرسپترون ورودی برای پرسپترونهای بعدی خواهد بود و در نهایت، پرسپترون آخر خروجی نهایی را تولید خواهد کرد که مشخص میکند آیا سطح لمسی داغ است یا خیر. این نمونه نشان میدهد که چگونه با استفاده از پرسپترون به عنوان واحد سادهتر و شبکههای عصبی پیچیدهتر، میتوانیم به تشخیص و پیشبینی ویژگیها و الگوهای پیچیدهتری مانند لمس سطح داغ بپردازیم.
قانون یادگیری پرسپترون
قانون یادگیری پرسپترون، یک قانون ساده و اساسی برای تنظیم وزنها در یک پرسپترون است. این قانون بر اساس ایدهی یادگیری ماشین بر پایهی ادراک بوده و به پرسپترون امکان میدهد تا به صورت خودکار وزنهای خود را بر اساس ورودیها و خروجیها تنظیم کند. قانون یادگیری پرسپترون به صورت زیر تعریف میشود.
ابتدا، وزنها به صورت تصادفی مقداردهی میشوند. ورودیها را با وزنها ضرب میکنیم و سپس نتیجه را به تابع فعالسازی پرسپترون (معمولا تابع سیگمویدی) میدهیم تا خروجی را بهدست آوریم. خروجی به ست آمده را با خروجی مورد انتظار مقایسه میکنیم تا خطا را محاسبه کنیم. وزنها را بر اساس خطا تنظیم میکنیم. اگر خطا مثبت است (خروجی باید بیشتر از خروجی مورد انتظار باشد)، وزنها را افزایش میدهیم. اگر خطا منفی است (خروجی باید کمتر از خروجی مورد انتظار باشد)، وزنها را کاهش میدهیم. مراحل فوق را تکرار میکنیم تا خطا به مقدار کمتری برسد و وزنها به مقادیر بهینه نزدیک شوند. وقتی که خطا به مقدار کمتری رسید و وزنها به مقادیری نزدیک به بهینه رسیدند، فرایند یادگیری پایان مییابد و پرسپترون آماده استفاده است. این قانون یادگیری پرسپترون به صورت تک جزیی از فرآیند یادگیری شبکههای عصبی عمیق (Deep Neural Networks) استفاده میشود. در شبکههای عصبی عمیق، این قانون به صورت تکراری برای هر لایه و واحد پردازشگر اعمال میشود تا وزنها به صورت تدریجی و بهینهتر تنظیم شوند.
شبکه عصبی پرسپترون یک لایه
شبکه عصبی پرسپترون یک لایه (Single-Layer Perceptron) یک نوع سادهتر از شبکه عصبی پرسپترون چند لایه است. در این نوع شبکه، تنها یک لایه پرسپترون وجود دارد که بین ورودی و خروجی قرار دارد. در واقع، این لایه تنها شامل یک گروه از پرسپترونها است که هر کدام با یک وزن متصل به ورودیها هستند و خروجی خطی را ارائه میدهند. شبکه عصبی پرسپترون یک لایه در واقع یک مدل خطی است و میتواند برای مسایل سادهتری مانند دستهبندی دادهها با دو کلاس استفاده شود. این شبکه قادر است یک خط تصمیم را در فضای ورودی تعیین کند، که با استفاده از وزنها و تابع فعالسازی (مانند تابع سیگموید یا تابع آن) به ورودیها اعمال میشود.
برای آموزش شبکه عصبی پرسپترون یک لایه، معمولا از الگوریتم یادگیری پسانتشار خطا (Backpropagation) استفاده میشود. این الگوریتم با محاسبه خطا و تنظیم وزنها به صورت پسرو، وزنها را بهبود میبخشد تا خطای شبکه کاهش یابد و دستهبندی بهتری انجام شود.
شبکه عصبی پرسپترون چند لایه
شبکه عصبی پرسپترون چند لایه (Multi-Layer Perceptron) از چندین لایه پرسپترون تشکیل میشود که به صورت متوالی و به هم متصل میشوند. هر لایه شامل یک یا چند پرسپترون است و خروجی یک لایه به عنوان ورودی لایه بعدی استفاده میشود. یک شبکه عصبی پرسپترون چند لایه شامل سه نوع لایه است. لایه ورودی (Input Layer) که وظیفهاش دریافت ورودیهای شبکه است. هر نقطه ورودی در این لایه با یک پرسپترون متناظر قرار میگیرد. تعداد نقاط ورودی این لایه برابر با تعداد ویژگیهای ورودی است.
لایههای پنهان (Hidden Layers) که وظیفه انجام محاسبات پیچیده و استخراج ویژگیهای مورد نیاز برای تشخیص الگوها را دارند. هر لایه پنهان شامل چندین پرسپترون است و خروجی هر پرسپترون در یک لایه مخفی به عنوان ورودی پرسپترونهای لایه بعدی استفاده میشود. تعداد لایههای پنهان و تعداد پرسپترونها در هر لایه پنهان بنابرنیاز تعیین میشود. لایه خروجی (Output Layer) وظیفه تولید خروجی شبکه را برعهده دارد. هر پرسپترون در این لایه با یک نقطه خروجی متناظر قرار میگیرد. تعداد پرسپترونها در این لایه بسته به تعداد دستهبندیها یا ویژگیهای خروجی مورد نظر تعیین میشود. شبکه عصبی پرسپترون چند لایه با استفاده از الگوریتم یادگیری و تنظیم وزنها (مانند الگوریتم پسانتشار خطا) و با تکرار مراحل محاسبه خروجی، بررسی خطا و تنظیم وزنها، به تدریج وزنهای بهینه را برای دستیابی به نتایج دقیقتر در تشخیص و پیشبینی الگوها و ویژگیهای مورد نظر تنظیم میکند.
بخوانید: تجهیزات پسیو شبکه چیست ؟



بدون دیدگاه